TED aka Twitter-based Exploit Detector es un bot en Twitter que nos informará cuando se publique una prueba de concepto o exploit en Twitter, síguelo en @alexfrancow_sec
Introducción
Hola a todos y bienvenidos al segundo post de mi blog, esta vez en Español. Hace aproximadamente unos 3 meses estuve desarrollando una aplicación que me permitia sacar todos los tweets, repositorios y enlaces que contuviesen un determinado CVE mostrando con gráficas; recuentos de tweets, retweets y likes, con esos datos y gracias a los algoritmos de Machine Learning podía identificar que tweets contenian una posible prueba de concepto/exploit, dejo el enlace de YouTube: NLP to detect Exploits on Twitter
Debido a que actualmente me está siendo muy dificil sacar tiempo para poder continuar con el desarrollo de la aplicación, en esta semana santa (2 días), se me ocurrió que podía simplificarlo mucho más y tener algo provisional para que me alertase de cuando se publicasen pruebas de concepto de exploits en Twitter. A continuación os detallo el desarrollo de TED.
API de Twitter
Si tenéis twitter y estáis en el mundo de la ciberseguridad, sabréis que es una plataforma muy importante, ya que te mantiene actualizado en todo momento de nuevas vulnerabilidades, nuevos exploits, nuevos zero-days o nuevas amenazas que surgen en el mundo. Siguiendo con el tema principal de la aplicación, mi idea fue la siguiente; crear un bot que hiciese retweets a los tweets que tuviesen una prueba de concepto o exploit para de esta manera activando la campana en ese perfil me alertase de cuando se publicase algo, asi todo el mundo podría seguir al bot y mantenerse informado también.
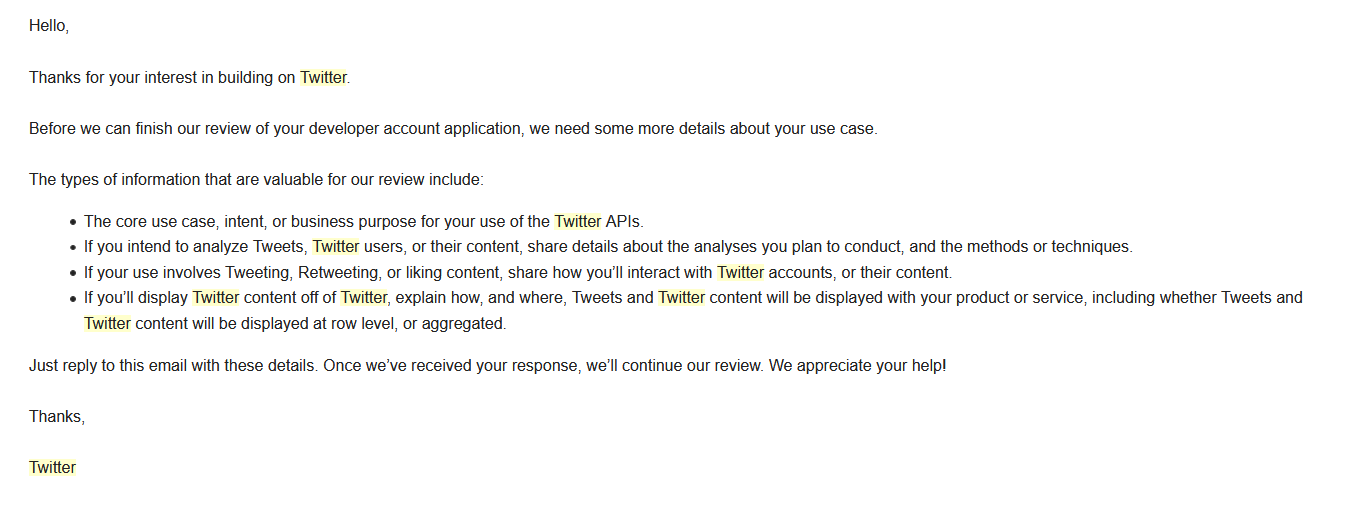
El bot ataca a varios endpoints de la API de twitter, uno de ellos es donde se realiza un streaming de todos los tweets, pero para consumir de dicha API es necesario tener una cuenta de desarrollador y para conseguirla es necesario enviar un email mencionando los intereses en utilizar la API.
Una vez aprobada por el equipo de Twitter, en el panel de desarrollador saldrá el proyecto que nos han creado, en este caso para propósitos académicos se habilitará el acceso a la V1.1 y a la V2 de la API.
Desde el mismo panel es donde se generan los tokens (API Key & Secret y el Bearer Token) que se utilizarán para la aplicación en Python.
Generación del Dataset y creación del Modelo
Teniendo ya acceso a la API de Twitter solo quedaría entrenar los algoritmos correspondientes que hacen que se pueda detectar cuando un Tweet se trata de una PoC/Exploit y cuando no. Para ello se descargarán todos los tweets que contengan “CVE-“ de los años 2019-2020 y se pasaran a .csv, existe una app llamada twint desarrollada en python que hará por nosotros este trabajo:
# Get old tweets
https://github.com/twintproject/twint
conda install -c anaconda git
pip3 install twint
pip3 install --user --upgrade git+https://github.com/twintproject/twint.git@origin/master#egg=twint
# Collect Tweets that were tweeted before 2020.
twint -s "cve-" --year 2020 -o cves-2019.csv --csv
# Collect Tweets that were tweeted since 2015-12-20 00:00:00.
twint -s "CVE-" --since 2015-12-20
Una vez descargados, se necesita identificar que tweet es una PoC/Exploit y cual no, un proceso manual que se basa en abrir el .csv e ir linea por linea marcando 1 o 0 en función si vemos que se trata de un exploit o no. Esto es necesario para el algoritmo de clasificación que vamos a utilizar ya que al ser supervisado tenemos que clasificar nosotros el dataset poniendo etiquetas (labeled data), en este caso la etiqueta ‘exploit’ que será igual a 1 o 0.
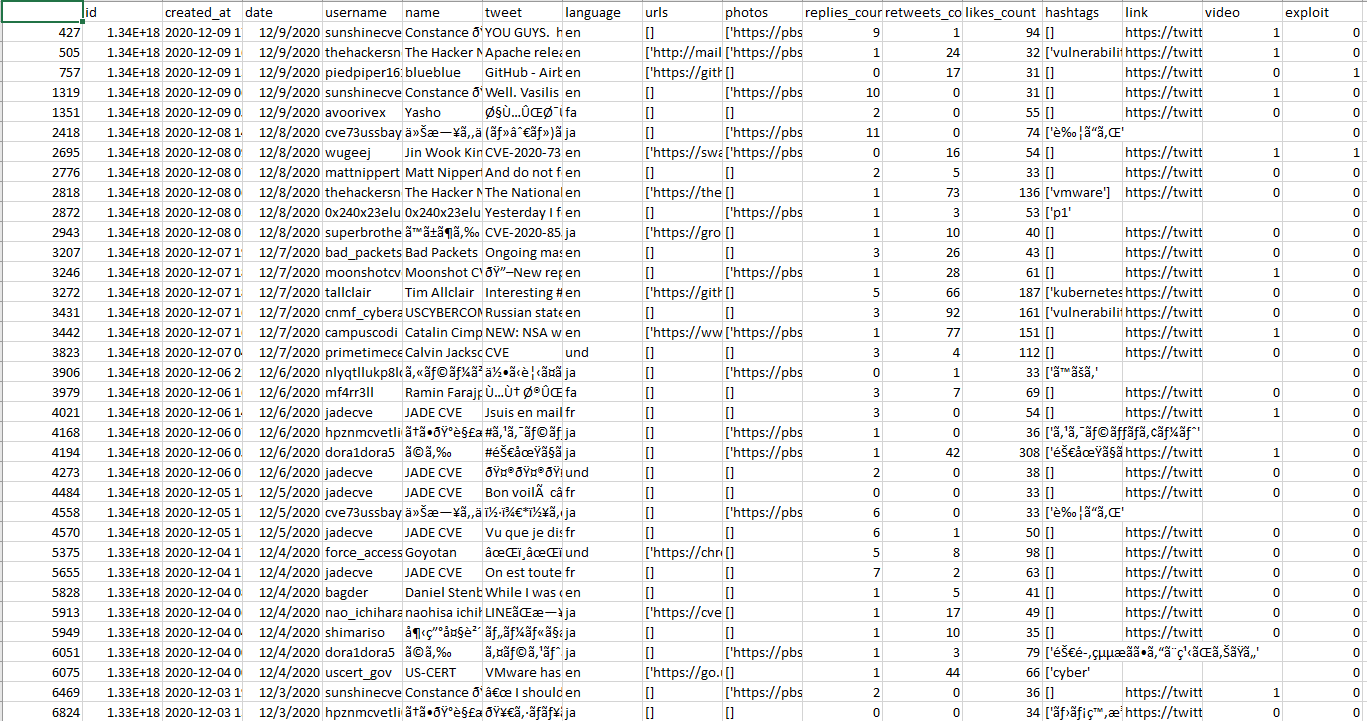
Explicación del Algoritmo
Para esta aplicación se clasificaron muy pocos tweets debido al tiempo de desarrollo, en total fueron 629. Una vez generado el dataset el modelo fue entrenando siguiendo el algoritmo MultinomialNB, un tipo de algoritmo del conjunto Naive Bayes, una clase especial de algoritmos de clasificación de Machine Learning que se basan en una técnica de clasificación estadística llamada “teorema de Bayes”, como se mencionó anteriormente supervisado.
Estos modelos son llamados algoritmos “Naive” y en ellos se asume que las variables predictoras son independientes entre sí. En otras palabras, que la presencia de una cierta característica en un conjunto de datos no está en absoluto relacionada con la presencia de cualquier otra característica.
Un claro ejemplo sería:
Supongamos que estamos construyendo un clasificador que dice si un texto es sobre deportes o no. Nuestros datos de entrenamiento tienen 5 frases:
| Texto | Deporte |
|---|---|
| “A great game” | Sports |
| “The election was over” | Not sports |
| “Very clean match” | Sports |
| “A clean but forgettable game” | Sports |
| “It was a close election” | Not sports |
Ahora bien, ¿a qué etiqueta pertenece la frase: A very close game?
Dado que Naive Bayes es un clasificador probabilístico, queremos calcular la probabilidad de que la frase “A very close game” sea deportes y la probabilidad de que no sea deportes. Por lo que, tomamos el más grande. Escrito matemáticamente, lo que queremos es P (Sports | A very close game): la probabilidad de que la etiqueta de una frase sea Deportes dado que la oración es “A very close game”.
¿Cómo calculamos estas probabilidades? Lo primero que debemos hacer al crear un modelo de aprendizaje automático es decidir qué usar como características. Llamamos características a las piezas de información que tomamos del texto y le damos al algoritmo para que pueda hacer su magia. Por ejemplo, si estuviéramos clasificando la salud, algunas características podrían ser la altura, el peso, el sexo, etc. de una persona. Excluiríamos las cosas que tal vez se conozcan pero que no sean útiles para el modelo, como el nombre de una persona o su color favorito.
Sin embargo, en este caso, ni siquiera tenemos funciones numéricas. Solo tenemos texto. Necesitamos convertir de alguna manera este texto en números en los que podamos hacer cálculos.
¿Asi que que hacemos? Usamos frecuencias de palabras. Es decir, ignoramos el orden de las palabras y la construcción de oraciones, y tratamos cada documento como un conjunto de palabras que contiene. Nuestras características serán los recuentos de cada una de estas palabras. Aunque pueda parecer un enfoque demasiado simplista, funciona sorprendentemente bien.
Teorema de Bayes
Ahora necesitamos transformar la probabilidad que queremos calcular en algo que se pueda calcular usando frecuencias de palabras. Para ello, utilizaremos algunas propiedades básicas de las probabilidades y el teorema de Bayes.
El teorema de Bayes es útil cuando se trabaja con probabilidades condicionales (como lo estamos haciendo aquí), porque nos proporciona una forma de revertirlas:
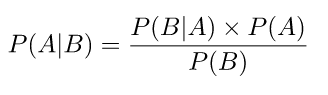
En nuestro caso, tenemos P (Sports | A very close game), por lo que usando este teorema podemos revertir la probabilidad condicional:
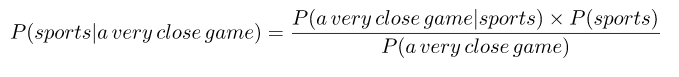
Dado que para nuestro clasificador solo estamos tratando de averiguar qué etiqueta tiene una mayor probabilidad, podemos descartar el divisor, que es el mismo para ambas etiquetas, y simplemente comparar
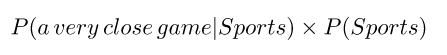
con
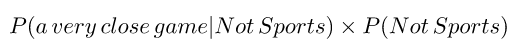
¡Esto es mejor, ya que podríamos calcular estas probabilidades! Simplemente cuenta cuántas veces aparece la frase “A very close game” en la etiqueta Sports, divídala por el total y obten P (A very close game) | Sports).
Pero, hay un problema: “A very close game” no aparece en nuestros datos de entrenamiento, por lo que esta probabilidad es cero. A menos que cada oración que queremos clasificar aparezca en nuestros datos de entrenamiento, el modelo no será muy útil. Entonces aquí viene la parte ingenua: asumimos que cada palabra en una oración es independiente de las demás. Esto significa que ya no estamos mirando oraciones completas, sino palabras individuales. Entonces, para nuestros propósitos, “esta fue una fiesta divertida” es lo mismo que “esta fiesta fue divertida” y “esta fue una fiesta divertida”.
Escribimos esto como:
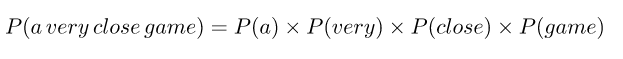
Esta suposición es muy sólida pero muy útil. Es lo que hace que este modelo funcione bien con pocos datos o datos que pueden estar mal etiquetados. El siguiente paso es simplemente aplicar esto a lo que teníamos antes:
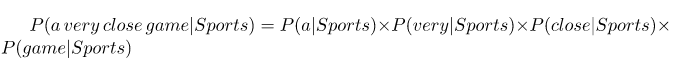
Y ahora, todas estas palabras individuales aparecen varias veces en nuestros datos de entrenamiento, y podemos calcularlas.
El paso final es simplemente calcular cada probabilidad y ver cuál resulta ser mayor.
Calcular una probabilidad solo cuenta en nuestros datos de entrenamiento.
Primero, calculamos la probabilidad a priori de cada etiqueta: para una oración dada en nuestros datos de entrenamiento, la probabilidad de que sea Sports P (Sports) es ⅗. Entonces, P (No Sports) es ⅖. Eso es bastante fácil.
Entonces, calcular P (Game | Sports) significa contar cuántas veces aparece la palabra “Game” en los textos deportivos (2) dividido por el número total de palabras en deportes (11). Por lo tanto,
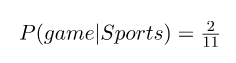
Sin embargo, nos encontramos con un problema aquí: “close” no aparece en ningún texto de deportes. Eso significa que P (close | Sports) = 0. Esto es bastante inconveniente ya que lo vamos a multiplicar con las otras probabilidades, por lo que terminaremos con
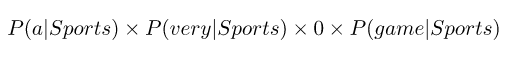
Esto es igual a 0, ya que en una multiplicación si uno de los términos es cero, se anula todo el cálculo. Hacer las cosas de esta manera simplemente no nos da ninguna información en absoluto, por lo que tenemos que encontrar una manera de evitarlo.
¿Cómo lo hacemos? Al usar algo llamado suavizado de Laplace: agregamos 1 a cada conteo para que nunca sea cero. Para equilibrar esto, agregamos el número de palabras posibles al divisor, por lo que la división nunca será mayor que 1. En nuestro caso, las palabras posibles son:
['a', 'great', 'very', 'over', 'it', 'but', 'game', 'election', 'clean', 'close', 'the', 'was', 'forgettable', 'match']
Dado que el número de palabras posibles es 14, aplicando suavizado obtenemos que
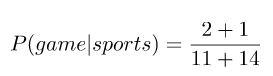
Los resultados completos son:
| Word | P (word Sports) | P (word Not Sports) |
|---|---|---|
| a | (2 + 1) ÷ (11 + 14) | (1 + 1) ÷ (9 + 14) |
| very | (1 + 1) ÷ (11 + 14) | (0 + 1) ÷ (9 + 14) |
| close | (0 + 1) ÷ (11 + 14) | (1 + 1) ÷ (9 + 14) |
| game | (2 + 1) ÷ (11 + 14) | (0 + 1) ÷ (9 + 14) |
Ahora solo multiplicamos todas las probabilidades y vemos quién es más grande:
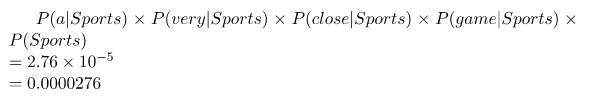
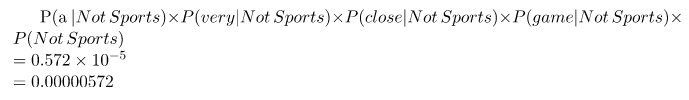
Nuestro clasificador le da a “A very close game” la etiqueta de Deportes.
Esta explicación que me pareció tan fácil de entender fué sacada de: https://monkeylearn.com/blog/practical-explanation-naive-bayes-classifier/
Aplicando la teoría
Después de la explicación teorica, ahora el primer paso para comenzar a utilizar el algoritmo descrito anteriormente será importar el dataset en el que se ha etiquetado cada tweet.
import pandas as pd
pd.options.display.float_format = '{:.0f}'.format
columns = "id,date,username,tweet,exploit"
df = pd.read_csv('DATASET.csv', usecols=columns.split(","))
Una vez importado llega la parte más importante en el campo del Machine Learning, y es pre-procesar los datos con funciones como; sustitución de URLs y nombres de usuario por palabras clave, eliminación de signos de puntuación y la conversión a minúsculas, y la normalización del texto (stemmer, lemmatize).
def remove_URL(x):
return re.sub(r"http\S+", "", x)
def tokenize(x):
tokenizer = TweetTokenizer()
return tokenizer.tokenize(x.lower())
def tokenize_remove_regex(x):
listToStr = ' '.join([str(elem) for elem in x])
tokenizer = RegexpTokenizer(r'http|2019|2018|cve|2020| |\.|,|:|;|!|\?|\(|\)|\||\+|\'|"|‘|’|“|”|\'|\’|…|\-|–|—|\$|&|\*|>|<|\/|\[|\]', gaps=True)
return tokenizer.tokenize(listToStr)
def stemmer(x):
stemmer = PorterStemmer()
return ' '.join([stemmer.stem(word) for word in x])
def lemmatize(x):
lemmatizer = WordNetLemmatizer()
return ' '.join([lemmatizer.lemmatize(word) for word in x])
Stemmer: es el proceso de producir variantes morfológicas de una palabra raíz/base. Un algoritmo de derivación reduce las palabras “chocolates”, “chocolatey”, “choco” a la raíz de la palabra, “chocolate” y “recuperación”, “recuperado”, “recupera” se reduce a la raíz “recuperar”.
Aplicando esa serie de funciones quedaría un dataframe como el siguiente:
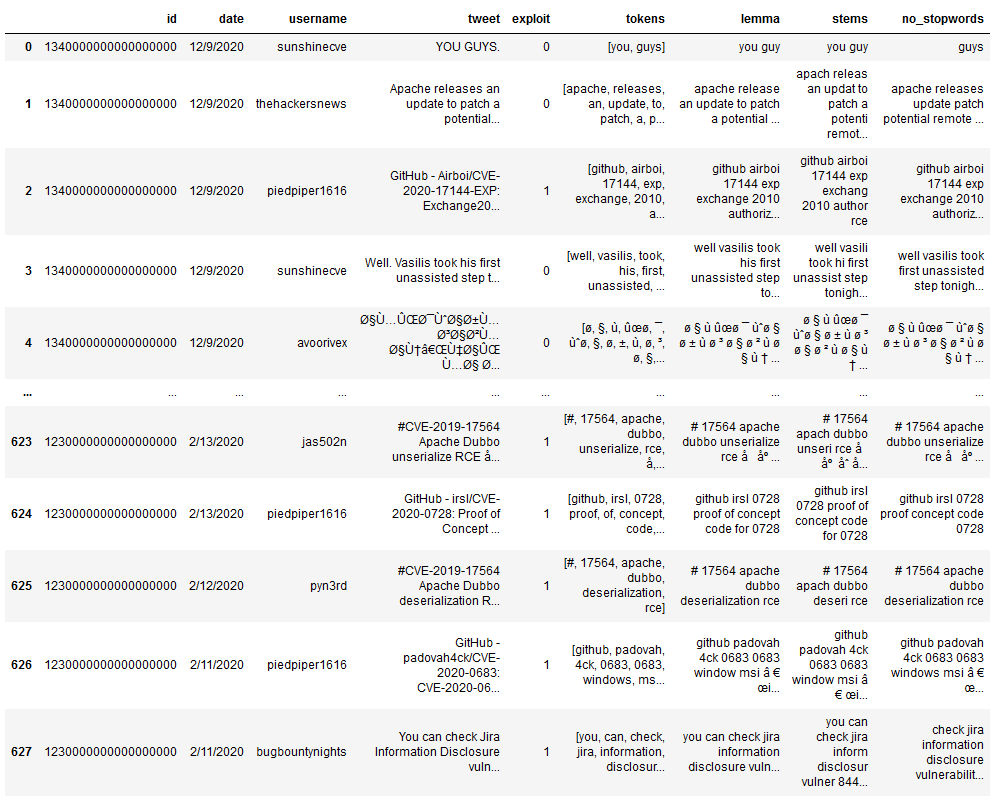
La parte final y más importante de nuestro procesamiento de texto es convertir estas cadenas en vectores. Los modelos que estamos usando requerirán que nuestras características de texto vengan en forma de vectores de números y las dos formas más comunes de hacerlo son CountVectorizer y TfidfVectorizer de sklearn.
Sin embargo, dos términos importantes a conocer son documento y corpus. Un documento es cada fragmento de texto individual, en nuestro caso cada publicación, mientras que el corpus son todos los documentos. Básicamente, estos vectorizadores crean un vocabulario que contiene cada palabra presente en el corpus y luego buscan en cada documento cada palabra.
CountVectorizer proporciona un recuento simple de cada palabra por documento, mientras que TfidfVectorizer divide el recuento por la frecuencia inversa del documento, el valor de cada token aumenta proporcionalmente al número de veces que una palabra aparece en el documento, pero es compensada por la frecuencia de la palabra en la colección de documentos, lo que permite manejar el hecho de que algunas palabras son generalmente más comunes que otras.
Una vez explicada la teoría es hora de crear el modelo, para ello haremos un split de nuestro dataframe y asi dividir las matrices de datos en dos subconjuntos: para entrenar datos y para probar datos. Con esta función, no es necesario dividir el conjunto de datos manualmente.
# Train/test
X = df['stems']
y = df['exploit']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 13)
De forma predeterminada, Sklearn train_test_split hará particiones aleatorias para los dos subconjuntos.
Vamos a emplear pipelines y grid searching para hacer que este proceso sea más ágil y eficiente. Una pipeline es una herramienta que nos permite unir un transformador (nuestro vectorizador de texto) y un modelo (nuestro clasificador, naive Bayes). Gridsearching es una herramienta para buscar diferentes combinaciones de parámetros de ajuste.
# Se crea una canalización con un vectorizador y nuestro clasificador Naive Bayes:
pipe_mnnb = Pipeline(steps = [('tf', TfidfVectorizer()), ('mnnb', MultinomialNB())])
# Parameter grid
pgrid_mnnb = {
# Max_features is the maximum number of words to include in the vocabulary. We will test max vocab sizes of 1000, 2000, and 3000 words.
'tf__max_features' : [1000, 2000, 3000],
# Stop_words are common words that can be filtered out when creating the vocabulary- read about them here. We will test removing stopwords against leaving them in.
'tf__stop_words' : ['english', stop_words_alexfrancow],
# ngram_range allows our model to look at individual words as well as word pairs. For example, the string “I like black cats” would get tokenized into “I”, “I like”, “like”, “like black”, “black”, “black cats”, “cats”. We will test using ngrams of 1 and 2 against just single words.
'tf__ngram_range' : [(1,1),(1,2)],
# Use_idf is the one we mentioned before. This will test a model that fits a TfidfVectorizer against one that fits a CountVectorizer.
'tf__use_idf' : [True, False],
'mnnb__alpha' : [0.1, 0.5, 1]
}
gs_mnnb = GridSearchCV(pipe_mnnb, pgrid_mnnb, cv=5, n_jobs=-1)
gs_mnnb.fit(X_train, y_train)
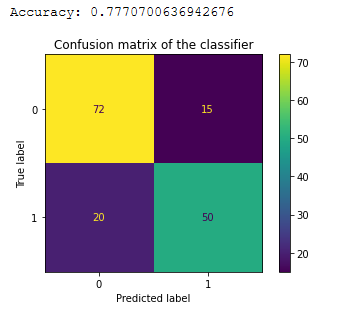
Se aprecia que el entrenamiento con 629 tweets da un Accuracy de 0.77, el accuracy es la precisión de casos clasificados correctamente, si la exactitud es menor o igual al 50% el modelo no será útil ya que sería lanzar una moneda al aire para tomar decisiones. Para que sea considerado fiable el porcentaje debería ser un 90%:
# Confusion matrix
import matplotlib.pyplot as plt
from sklearn.metrics import plot_confusion_matrix, accuracy_score
y_pred_class = gs_mnnb.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred_class))
plot_confusion_matrix(gs_mnnb, X_test, y_test)
plt.title('Confusion matrix of the classifier')
plt.show()
Como se puede apreciar en la matriz de confusión, la diagonal principal contiene la suma de todas las predicciones correctas, la otra diagonal refleja los errores del clasificador: los falsos positivos o los falsos negativos.
Una vez entrenado el modelo simplemente quedaría por consumir de la API de Twitter y sacar los tweets en tiempo real, para ello se hará uso del endpoint search/stream, cabe recalcar que al no ser interesantes todos los tweets antes se deberá aplicar una regla y filtrar asi los tweets que contengan el string “CVE-“, para ello se usará el endpoint stream/rules el cual permitirá crear una regla que además omita los retweets y los replies, la consulta sería la siguiente:
sample_rules = [
{'value': '"CVE-" -is:retweet -is:reply',
'tag': 'Exploits'},
]
payload = {"add": sample_rules}
response = requests.post(
"https://api.twitter.com/2/tweets/search/stream/rules",
headers=headers,
json=payload,
)
La documentación sobre el stream y las reglas podemos consultar los siguientes enlaces:
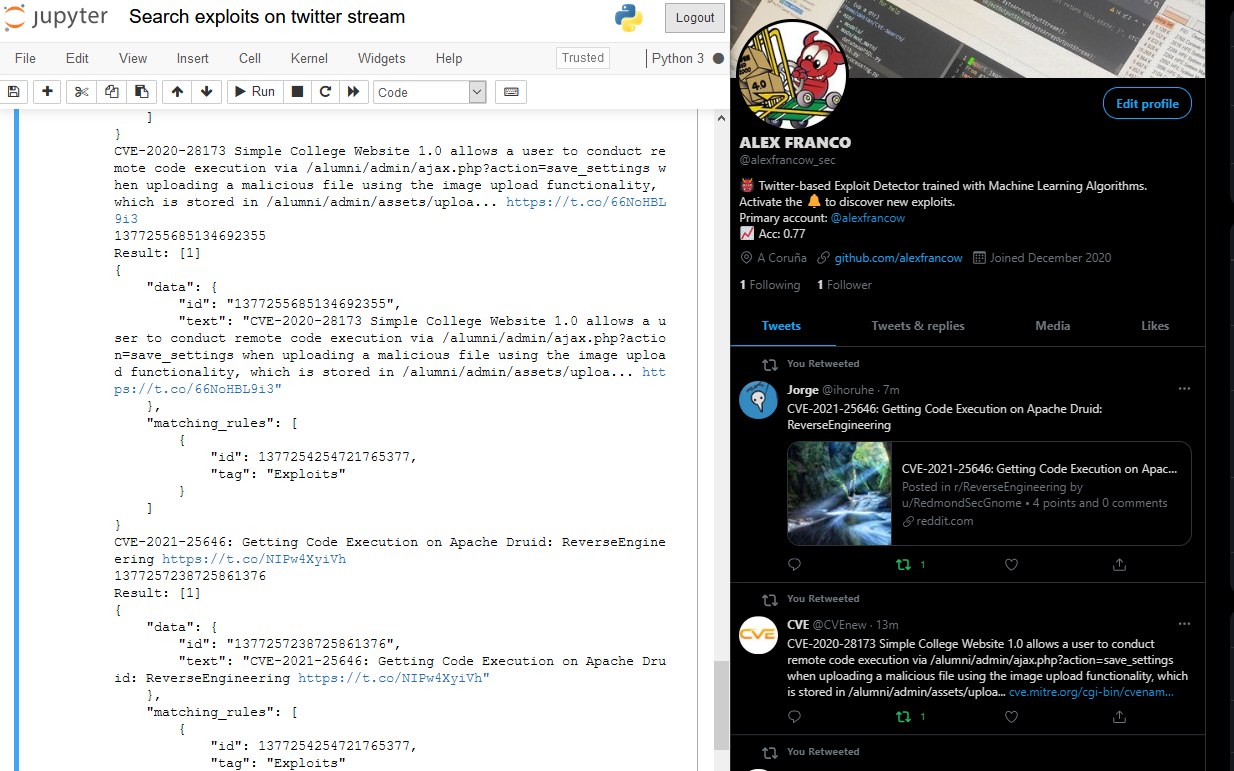
Llegados hasta aqui solo nos queda una pregunta por responder, ¿es funcional?
Pues si, el bot es funcional, pero todavía no es fiable ya que solo tiene un 77% de precisión por lo tanto el bot categoriza algunos tweets que no son exploits, precisión que se podrá mejorar; etiquetando más tweets del dataset y entrenando de nuevo el modelo o pre-procesando los datos de otra manera.
PoC del bot
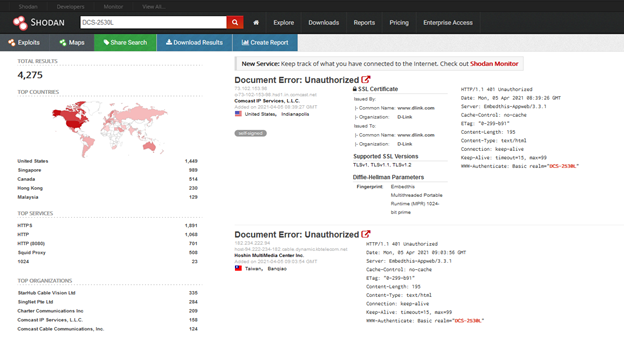
De momento todo fue teorico, veamos un caso que ha considerado como exploit:
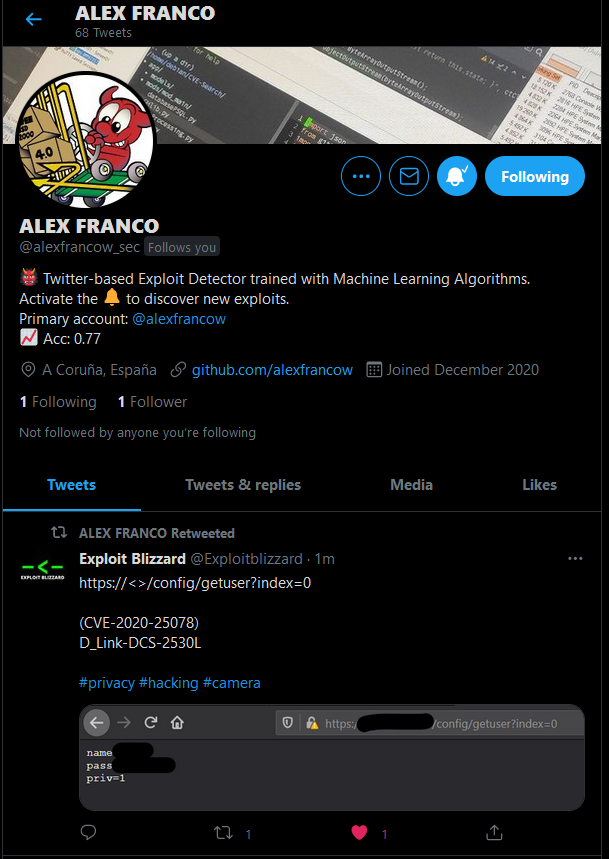
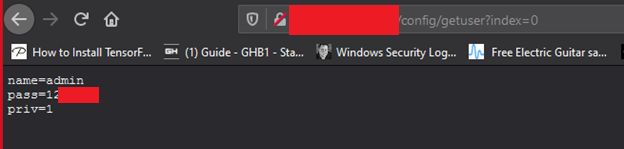
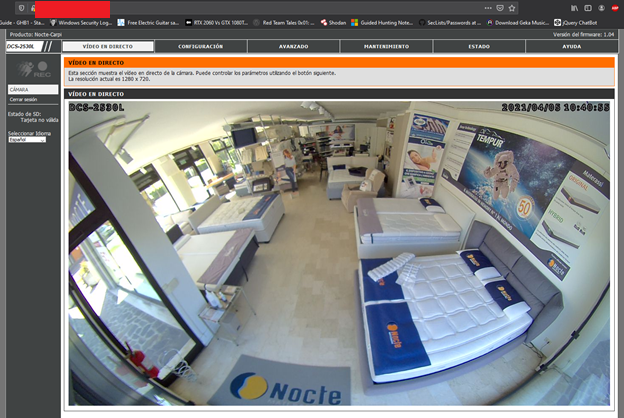
Efectivamente es un exploit para la vulnerabilidad CVE-2020-25078 que afecta a las camaras D_Link-DCS-2530L, una vulnerabilidad vieja pero ejemplifica bien el funcionamiento del bot, si nos vamos a shodan.io y buscamos por ese modelo de camara nos aparecerán 4275 resultados, si entramos en una IP del listado y añadimos a la url “/config/getuser?index=0” veremos que en muchos casos es posible explotarlos, consiguiendo de esta manera las credenciales de la cuenta administrador que nos permiten entrar en la camara y ver en tiempo real el video capturado.