




TED in ELK
Hace un tiempo desarrollé una aplicación llamada TED (Twitter-based Exploit Detector), más bien una PoC, la cual era capaz de detectar Exploits y pruebas de concepto de vulnerabilidades en tweets a través de algoritmos de Inteligencia Artificial tales como el multinomialNB y la API de Twitter. Con este modelo se ha procedido a desarrollar un conector para ELK.
El articulo es posible encontrarlo en la siguiente entrada del blog:
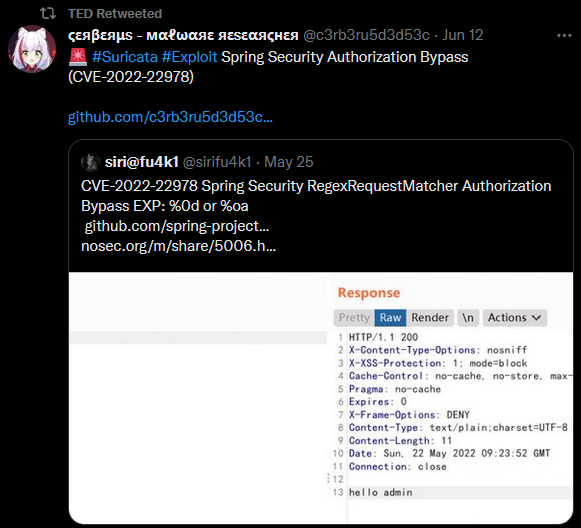
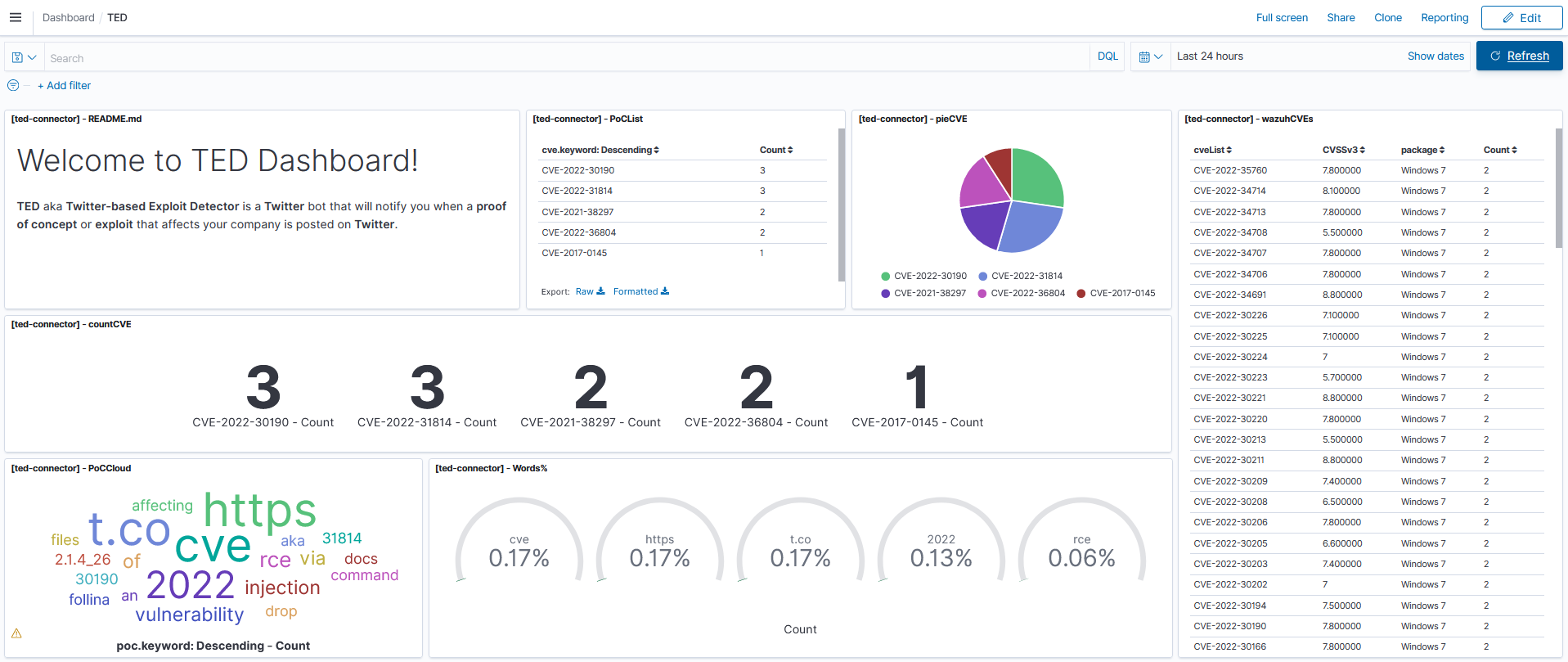
TED ofrece una sinergia muy alta con tecnologías Open Source como Wazuh, OpenSearch y Kibana. Estas permiten mantener un listado de paquetes instalados en los diferentes equipos registrados en la plataforma, y permiten mapear ese listado con bases de datos de CVEs con el módulo vulnerability-detector de Wazuh. Por lo que es posible visualizar en tiempo real las vulnerabilidades que más afectación tienen en la compañía.
Además de esto, aporta dashboards para la correcta y eficaz visualización de los datos.
Este módulo es configurable a través del fichero ossec.conf.
<vulnerability-detector>
<enabled>yes</enabled>
<interval>5m</interval>
<ignore_time>6h</ignore_time>
<run_on_start>yes</run_on_start>
...
<!-- Aggregate vulnerabilities -->
<provider name="nvd">
<enabled>yes</enabled>
<update_from_year>2010</update_from_year>
<update_interval>1h</update_interval>
</provider>
</vulnerability-detector>
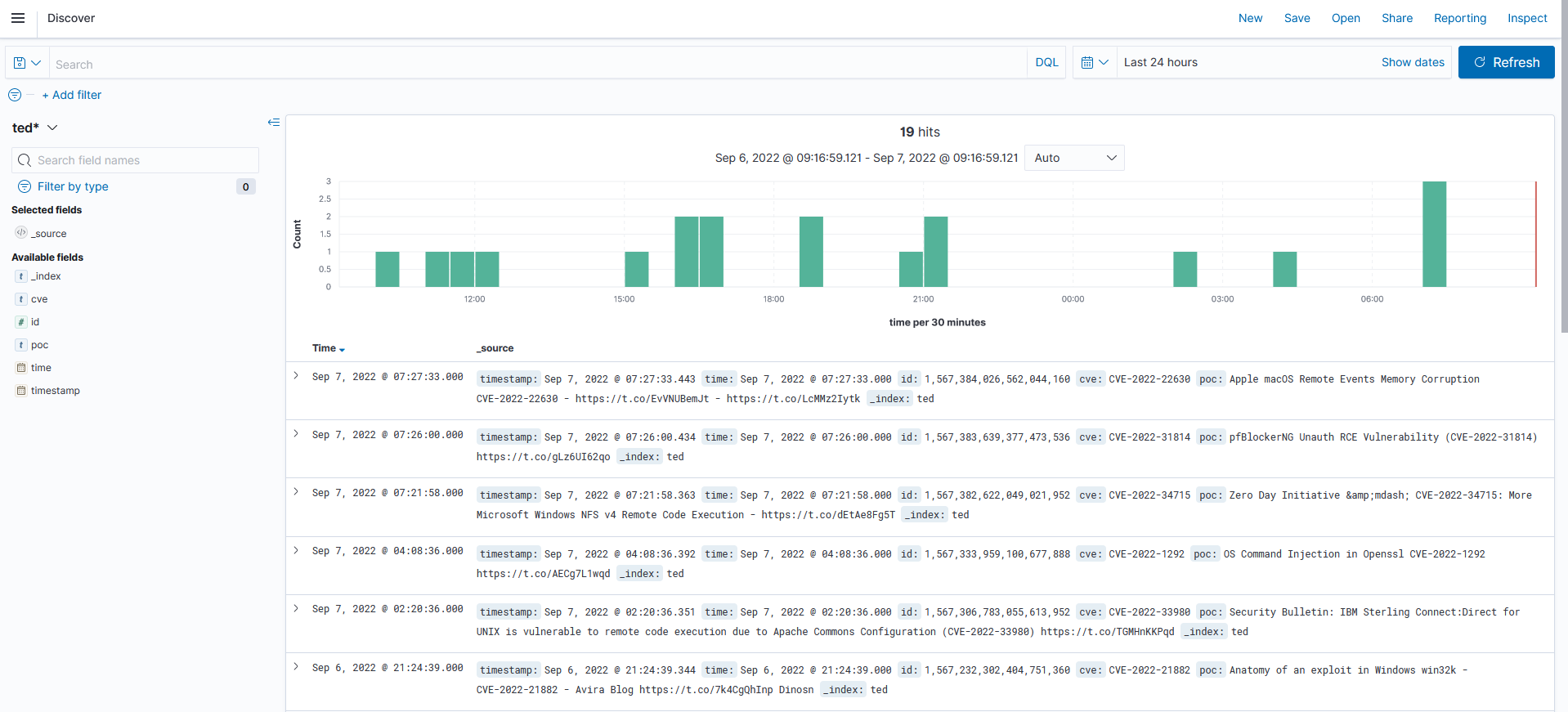
Estos datos, de CVEs aplicados a equipos, se almacenan en OpenSearch/ElasticSearch por lo que, es posible realizar consultas a la API y hacer uso de esos datos.
En el caso de TED, se realizan distintas peticiones y se almacenan en un array todos los CVEs encontrados.
cveList = WZ.getAllCves()
La lógica seguida para la aplicación se muestra en el siguiente diagrama.
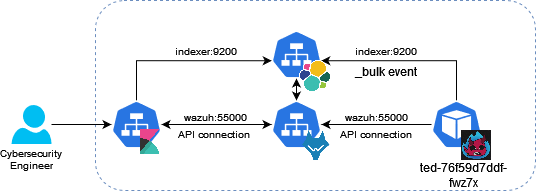
Como primer punto TED descarga el listado de CVEs que tienen afectación directa en la compañía donde se encuentre desplegada la solución. Con ese listado se mantiene escuchando el stream de Twitter en busca de posibles exploits, en caso de ser parseado por los algoritmos de Inteligencia Artificial y su resultado sea positivo, este hará un bulk del evento a la base de datos de OpenSearch/ElasticSearch y será consultado a través de unos dashboards de Kibana por un ingeniero, el cual dará prioridad a la hora de actualizar algún paquete, ya que habrá un incremento del riesgo relacionado con la vulnerabilidad.
Despliegue
Se ha desarrollado una imagen en Docker, la cual incorpora las siguientes variables de entorno que son necesarias para el correcto funcionamiento de la aplicación, además de hacer la aplicación totalmente escalable en cualquier escenario.
INDEXER_URL:string: - URL de OpenSearch/ElasticSearch.INDEXER_USERNAME:string: - Usuario de OpenSearch/ElasticSearch.INDEXER_PASSWORD:string: - Contraseña de OpenSearch/ElasticSearch.WAZUH_API_URL:string: - URL de Wazuh.API_USERNAME:string: - Usuario de la API de Wazuh.API_PASSWORD:string: - Contraseña de la API de Wazuh.BEARER_TOKEN:string: - Token de Twitter.TWITTER_APP_KEY:string: - Key de Twitter.TWITTER_APP_SECRET:string: - Secret de Twitter.ACCESS_TOKEN:string: - Access Token de Twitter.ACCESS_TOKEN_SECRET:string: - Secret del Access Token de Twitter.GET_ALL_TWS:bool: - Variable de control para realizar solo búsquedas de CVEs encontrados por Wazuh. El valorFalsepara búscar solo CVEs detectados por Wazuh.
Para desplegarlo simplemente es necesario ejecutar el siguiente comando:
# Build
docker-compose build
# Deploy
docker run -e TWITTER_APP_KEY="" \
-e TWITTER_APP_SECRET="" \
-e access_token="" \
-e access_token_secret="" \
-e bearer_token="" \
-e INDEXER_USERNAME="admin" \
-e INDEXER_PASSWORD="" \
-e GET_ALL_TWS="True" \
-e INDEXER_URL="" \
-e WAZUH_API_URL="" \
-e API_USERNAME="" \
-e API_PASSWORD="" docker_ted
Imagen pública de DockerHub:
alexfrancow/ted-connector:latest
Es posible desplegar el conector en Kubernetes, en los distintos clouds como: Azure, Google o AWS. Para ello se recomienda generar unos secrets para que estes no se encuentren hardcodeados en ningún fichero de configuración.
TWITTER_APP_KEY = ""
TWITTER_APP_SECRET = ""
ACCESS_TOKEN = ""
ACCESS_TOKEN_SECRET = ""
BEARER_TOKEN = ""
NAMESPACE=""
kubectl create secret generic ted-creds --from-literal=TWITTER_APP_KEY=$TWITTER_APP_KEY \
--from-literal=TWITTER_APP_SECRET=$TWITTER_APP_SECRET \
--from-literal=ACCESS_TOKEN=$ACCESS_TOKEN \
--from-literal=ACCESS_TOKEN_SECRET=$ACCESS_TOKEN_SECRET \
--from-literal=BEARER_TOKEN=$BEARER_TOKEN \
--namespace=$NAMESPACE -o yaml
INDEXER_USERNAME = ""
INDEXER_PASSWORD = ""
kubectl create secret generic indexer-creds --from-literal=username=$INDEXER_USERNAME \
--from-literal=password=$INDEXER_PASSWORD \
--namespace=$NAMESPACE -o yaml
API_USERNAME = ""
API_PASSWORD = ""
kubectl create secret generic wazuh-api-cred --from-literal=username=$API_USERNAME \
--from-literal=password=$API_PASSWORD \
--namespace=$NAMESPACE -o yaml
Los campos del evento que se almacena en OpenSearch/ElasticSearch son los siguientes:
{
"properties": {
"cve" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"time" : {
"type" : "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"id" : {
"type" : "long"
},
"timestamp" : {
"type" : "date",
"format": "epoch_second"
},
"poc": {
"type": "text",
"fielddata": true,
"fields" : {
"keyword" : {
"type" : "text",
"fielddata": true
}
}
}
}
}
Existe la posibilidad editar la función
pushCvede la claseIndexerpara agregar cualquier campo a mayores dentro de la variabledata. (src/main.py)
Demo
Conclusiones
El módulo funciona correctamente, y es posible agregarlo en producción bajo la supervisión de un ingeniero. Agregarlos con un timestamp en OpenSearch/ElasticSearch ayuda a ver como ha evolucionado una vulnerabilidad en Twitter y aporta métricas interesantes.
No es recomendable agregar un alertado automático, ya que se pueden producir demasiados falsos positivos. Para que este nivel de FPs sea menor, es necesario seguir entrenando el modelo de aprendizaje.
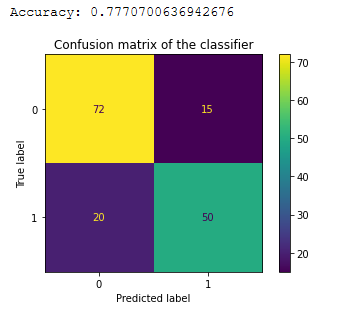
En la anterior entrada del blog, se muestra como aumentar el dataset.
El dataset, el modelo, y el notebook se encuentran en el repositorio.
src/dataset/DATASET.csv,src/notebooks/NLP-TED.ipynbysrc/models/NLP_Modelv1.joblib.
El scope del conector es limitado, ya que se centra solamente en Twitter. Es posible aumentarlo consumiendo de otras APIs, quizás Reddit, GitHub o GitLab y aumentar el scope. Para esto es necesario tener en cuenta que, sería necesario entrenar otro modelo de Machine Learning.